
銅線遇到了物理極限
AI 時代來臨,在同時間內處理更多的資料需求不斷增加,造成的結果是,不僅 AI 晶片越做越大,處理器越來越多,而且處理器和處理器之間需要更密集的連接,還要跨越更長的機架內距離。
然而,在傳統上負責連結的「銅線」,面臨了幾個無法迴避的物理瓶頸,造成了電子互連在 GPU 與記憶體間傳輸資料的根本限制。
在傳統設計裡,GPU 晶片產生的電訊號要跑過幾十公分的 PCB 銅走線,經過連接器,最後才到達插拔式光模組轉成光訊號。這一路上「訊號越來越差」,所以需要 SerDes* 電路拼命補償,非常耗電。所以傳統設計的功耗能源很大一部分,其實不是花在「運算」或「傳光」上,而是花在「讓電訊號撐過那幾十公分銅線」這件事上。
Nvidia 網路部門 SVP Shainer 解釋:銅的能力取決於距離和速度兩個因素;隨著速度不斷提高,銅的有效傳輸距離會越來越短,到某個臨界點就不夠用了。當 AI 集群需要跨多個機架互連數百顆 GPU 時,銅線的物理距離限制就成了一道難以橫越的鴻溝。
* SerDes(Serializer/Deserializer,序列化器/反序列化器)是一組很複雜的電路,負責在發送端把訊號「整理乾淨」推出去,在接收端把已經劣化的訊號「猜回來」還原。速度越高,SerDes 就要越用力補償,吃的電也越多。
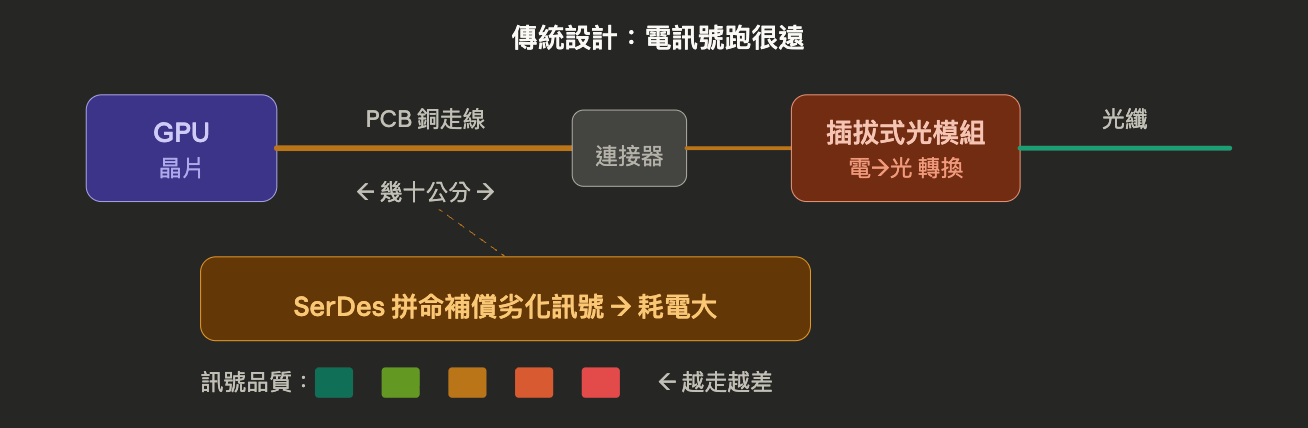
CPO 的設計則是把「光學引擎」跟「GPU」直接封裝在一起,電訊號只要走幾十毫米就能轉成光。路徑短了十倍,訊號幾乎沒有劣化,SerDes 不用那麼用力,功耗自然就降了下來。

CPO 的全名是 Co-Packaged Optics,中文叫「共封裝光學」。拆開來看:
Optics(光學):指的是用光來傳資料的元件,包括:雷射、調變器、光偵測器等等,合稱「光學引擎」(Optical Engine)。
Co-Packaged(共封裝):指的是把光學引擎跟主晶片(GPU 或交換晶片)封裝在同一個基板上,變成一個整體。
CPO 系統裡有兩個關鍵元件:
PIC(光子積體電路):用矽光子技術製作,裡面有雷射調變器和光偵測器,負責把電訊號轉成光、把光轉回電。
EIC(電子積體電路):負責驅動 PIC,處理訊號的編碼和解碼。
Nvidia 的光學引擎是用台積電的 COUPE 製程,把 EIC 堆疊在 PIC 上面,三個引擎組成一個可拆卸的光學子模組,每組提供 4.8Tbps 的吞吐量。 這代表光學元件是可更換的模組,而不是永久焊死在基板上,這解決了維修的顧慮。

傳統的插拔式光模組受限於訊號衰減、功耗和延遲,因為它們需要在交換晶片和光學引擎之間拉很長的電氣走線。CPO 則把光學引擎放到離交換晶片很近的位置,克服了這些限制。簡單來說,CPO 就是把「電轉光」的轉換器從遠處搬到晶片旁邊,讓電訊號只走幾毫米就變成光訊號。
AI 規模化是直接推手
Nvidia 的 GB200 系統把互連規模從 8 顆 GPU 推到 72 顆全對全拓撲,帶來了巨大的效能提升。但用銅線,這只能在單一機架內完成,對供電、散熱和製造都造成極大壓力。
要繼續擴大到 576 甚至 1152 顆 GPU 的規模,如果是做 NVLink72 或 NVLink144,銅線在距離上還行得通,就用銅;但要做到 1152 顆 GPU,同時還要跨越多個機架,銅線已經無法使用,必須靠 CPO。
同時,光學互連提供了更高的頻寬、更低的延遲、更遠的傳輸距離,能在 GPU 和加速器之間實現超快通訊。同時,光訊號不像電訊號那樣會互相干擾(串擾),可以通過波長分波多工(WDM)在單根光纖中同時傳輸多路訊號。
具體帶來什麼好處?
省電是最大的驅動力: 一個傳統 800G 的插拔式光模組大約吃電 16-17W,而 Nvidia CPO 交換器中的光學引擎加上外部雷射光源,每 800G 頻寬只需約 4-5W,功耗降低了約 73%。
黃仁勳在 GTC 2025 上算了一筆帳:每顆 GPU 需要六個插拔式光電轉換器,每個吃 30W。如果擴展到一百萬顆 GPU,光是這些轉換器就要吃掉大約 180MW,這個數字完全不可持續。
頻寬密度更高: 一個 AI 資料中心的單個伺服器機架裡可能包含兩英里的銅纜連接數百顆晶片。 CPO 用光纖取代這些銅纜,大幅縮減佈線體積,騰出空間塞更多運算能力。
光學中介層的頻寬密度可達 10 Tbps/mm,而銅互連只有約 3 Tbps/mm。當 GPU 數量從 8 顆擴展到數百、數千顆時,頻寬密度不夠的開始浮現,銅線與光中介層的差距也開始明顯。
CPO 就是「把光學轉換器從機器邊緣搬到晶片身邊」,核心目的是縮短電訊號的行走距離,從而大幅省電、提高頻寬密度,讓 AI 資料中心能擴展到百萬顆 GPU 的規模,AI 的光學革命正在無聲無息的進行。
現實是「銅+光」並存
值得一提的是,這不是一刀切的替換。Nvidia CEO 黃仁勳在 GTC 演講中明確表示:「我們會兩種都做」:機架內第一層用銅互連,第二層脊柱層用光學模組。業界預測銅線在單機架內的超短距連接仍將主導到 2028 年左右,但跨機架的大規模 GPU 集群必須依賴光學傳輸。
簡單來說:銅線在「短距離、少GPU」的場景依然好用又便宜,但 AI 把 GPU 集群推向了數千顆的規模,距離和頻寬需求已經超出銅的物理能力,光就成了唯一的出路。
